USE CASE |
|
| Title: | Mapping External Data and Schema |
| Short Description: | Use
cases for mapping linked datasets, vocabularies and
ontologies to KBpedia are described
|
| Problem: |
We want to extend KBpedia with domain or enterprise information to make
it more relevant to our specific domain needs or problem areas |
| Approach: | Our mapper includes standard baseline capabilities found in other mappers such as string and label comparisons, attribute comparisons, and the like. But, unlike conventional mappers, our mapper is able to leverage both the internal knowledge graph structure and its use of typologies, most of which do not overlap with one another, to add structural comparators as well. These capabilities lead to more automation at the front end of generating good, likely mapping candidates, leading to faster acceptance by analysts of the final mappings. This approach is in keeping with the philosophy to emphasize "semi-automatic" mappings that combine fast final assignments with the highest quality. Maintaining mapping quality is the sine qua non of knowledge-based artificial intelligence |
| Key Findings: |
|
There are many situations where we want to map entities, vocabulary terms, schema or ontologies to KBpedia. We may also want to find and remove duplicates for these items from one or more of the constituent datasets used. We have a general utility for these purposes called the mapper. Some uses for this mapper and how it differs from similar capabilities found elsewhere is the subject of this use case.
We do not believe in fully automated systems for such mappings. Though automatic mapping may be fast, and is one way to deal with the combinatorial issue of large-scale knowledge bases with thousands or millions of terms, in combination knowledge bases pose a number of challenges. These challenges may be summarized as: 1) different terms in different sources referring to the same thing; 2) similar terms in different sources referring to different things; and 3) duplicate terms within a single source or across multiple sources referred to in different ways. When mapping, it is important to maintain context and resolve these ambiguities (a process called "disambiguation") across sources.
Yet, given the combinatorial challenge, some degree of automation remains essential. Matching thousands of items in one source to thousands of items in another source is a factorial challenge. Manual approaches alone are simply too time consuming.
What we seek, therefore, are utilities that automatically narrow mapping candidates to a tolerable number of choices, including the "correct" ones, with potential mappings scored to help narrow even these candidate choices to the likely "correct" ones for final assignments. The combination of automatic initial screening with final manual vetting is known as a semi-automatic system. It is the approach that leads to the highest quality eventual structure. Automating as much as possible in the front end and then presenting the most viable mapping candidates for final selection is the key to make the overall mapping process as efficient and high quality as possible.
Most mapping frameworks work along similar lines. They use one or two datasets as sources of entities (or classes or vocabulary terms) to compare. The datasets can be managed by a conventional relational database management system, a triple store, a spreadsheet, etc. Then these mapping frameworks have complex configuration options that let the user define all kinds of comparators that will try to match the values of different properties that describe the items to be mapped in each dataset. Comparator types may be simple string comparisons, the added use of alternative labels or definitions, attribute values, or various structural relationships and linkages within the dataset. Then the comparison is made for all the entities (or classes or vocabulary terms) existing in each dataset. Finally, an entity similarity score is calculated, with some threshold conditions used to signal whether the two entities (or classes or vocabulary terms) are the same or not.
Our mapping utility employs all of these same techniques. However, in addition, our reliance on the coherent structure in KBpedia's knowledge graph (the KBpedia Knowledge Ontology, or KKO), gives us some significant additional power. As noted elsewhere, all of the 30 million entities and 85% of the reference concepts in KBpedia are organized under KBpedia's typology structure. We are able to leverage this structure with an addition to the mapper called the SuperType Comparator. The SuperType Comparator helps disambiguate mapping items based on their type(s) and the analysis of their types in the KBpedia Knowledge Ontology. The SuperType Comparator's role is to disambiguate the candidate items based on their type(s) by leveraging the disjointedness of the SuperType structure that governs the overall KBpedia structure. The SuperType Comparator greatly reduces the time needed to curate the deduplication or linkage tasks in order to determine the final mappings. This unique comparator greatly speeds the semi-automatic mapping task.
We first present a series of use cases for the mapper below, followed by an explanation of how the mapper works, and then some conclusions.
Usages Of The Mapper
When should the mapper, or other deduplication and mapping services, be used? While there are many tasks that warrant the usage of such a system, let's focus for now on some use cases related to KBpedia and machine learning in general.
Mapping Across Schema
One of the most important use cases is to use the mapper to link new vocabularies, schemas or ontologies to the KBpedia Knowledge Ontology (KKO). This is exactly what we did for the external ontologies and schemas that we have integrated into KBpedia. Creating such a mapping can be a long and painstaking process. The mapper greatly helps linking similar concepts together by narrowing the candidate pool of initial set of mappings, thereby increasing the efficiency of the analyst charged with selecting the final mappings between the two ontologies.
Creating 'Gold Standards'
In a separate use case noting the benefits of extending KBpedia with private datasets, we noted the creation of a 'gold standard' of 511 random Web pages where we validated the publisher of the web page by hand. That gold standard was used to measure the performance of a named entities recognition task. However, to create the actual gold standard, we had to check millions of entities across five datasets to see if that candidate publisher existed in any of them. The mapper enabled us to reduce to five mapper sessions (one for each dataset source) what would, under standard approaches, have required about 2500 search queries (5 * 511), an effort that would probably have taken at least one week to complete, including all of the steps needed to make the final choices.
Because of its front-end automation, the mapper needs only to be run against each of the five datasets, review the matches, find the missing ones by hand, and then merge the results into the final gold standard. We can build these gold standards in just a few hours.
Curating Unknown Entities
We also have an unknown entities tagger that is used to detect possible publisher organizations that are not currently existing in the KBpedia knowledge base. In some cases, what we want to do is to save these detected unknown entities into an 'unknown entities dataset'. Then this dataset will be used to review detected entities to include them back into the KBpedia knowledge base (such that they become new). In the review workflow, one of the steps should be to try to find similar entities to make sure that what was detected by the entities tagger was a totally new entity, and not a new surface form for that entity (which would become an alternative label for the entity and not an entirely new one). Such a duplicates check is straightforward in the workflow performed by the mapper.
How Does the SuperType Comparator Work?
Rather than focus on string comparisons, which are common to most all mappers, let's concentrate on the unique SuperType comparator within the mapper. For this example, let's consider the case of mapping music topics across two datasets, Wikipedia and the Musicbrainz database. One of the Musicbrainz entities we want to map to Wikipedia is the Attila music band, formed years ago with members Billy Joel and Jon Small. Attila also exists in Wikipedia, but it is highly ambiguous and may refer to multiple different things. If we based our linkage task to only work on the preferred and possible alternative labels, we would end up with a match to multiple other things in Wikipedia with a similar likelihood scores, yet with most matches incorrrect. The mapper SuperType comparator is able to remove these ambiguities.
Musicbrainz RDF dumps normally map a Musicbrainz group to a mo:MusicGroup. In the Wikipedia RDF dump the Attila rock band has a type dbo:Band. Both of these classes are linked to the KBpedia reference concept kbpedia:Band-MusicGroup. This means that the entities of both of these datasets are well connected into KBpedia.
Let's say that the mapper does detect that the Attila entity in the Musicbrainz dataset has 4 candidates in Wikipedia:
- Attila, the rock band
- Attila, the bird
- Attila, the film
- Attila, the album
If the comparison is only based on the preferred label, the likelihood will be the same for all these entities. However, what happens when we start using the SuperType Comparator and the KBpedia Knowledge Ontology?
First we have to understand the context of each type. Using KBpedia, we can determine that rock bands, birds, albums and films are disjoint according to their super types: kko:Animals, kko:Organizations kko:AudioInfo and kko:VisualInfo.
Now that we understand each of the entities the system is trying to link together, and their context within the KBpedia Knowledge Ontology, let's see how the mapper will score each of these entities based on their type to help disambiguate where labels are identical.
(println "mo:MusicGroup -> dbo:Band" (.compare stc-ex-compare "http://purl.org/ontology/mo/MusicGroup" "http://dbpedia.org/ontology/Band")) (println "mo:MusicGroup -> dbo:Bird" (.compare stc-ex-compare "http://purl.org/ontology/mo/MusicGroup" "http://dbpedia.org/ontology/Bird")) (println "mo:MusicGroup -> dbo:Film" (.compare stc-ex-compare "http://purl.org/ontology/mo/MusicGroup" "http://dbpedia.org/ontology/Film")) (println "mo:MusicGroup -> dbo:Album" (.compare stc-ex-compare "http://purl.org/ontology/mo/MusicGroup" "http://dbpedia.org/ontology/Album"))
| Classes | Similarity |
|---|---|
| mo:MusicGroup -> dbo:Band | 1.0 |
| mo:MusicGroup -> dbo:Bird | 0.2 |
| mo:MusicGroup -> dbo:Film | 0.2 |
| mo:MusicGroup -> dbo:Album | 0.2 |
In these cases, the SuperType Comparator did assign a similarity of 1.0 to the mo:MusicGroup and the dbo:Band entities since those two classes are equivalent. All the other checks returns 0.20. When the comparator finds two entities that have disjoint SuperTypes, then it assigns the similarity value 0.20 to them. Why not 0.00 if they are disjoint? Well, there may be errors in the knowledge base, so that setting the comparator score to a very low level, it is still available for evaluation, even though its score is much reduced.
Here is a graphical representation of how the SuperType Comparator works in this case:
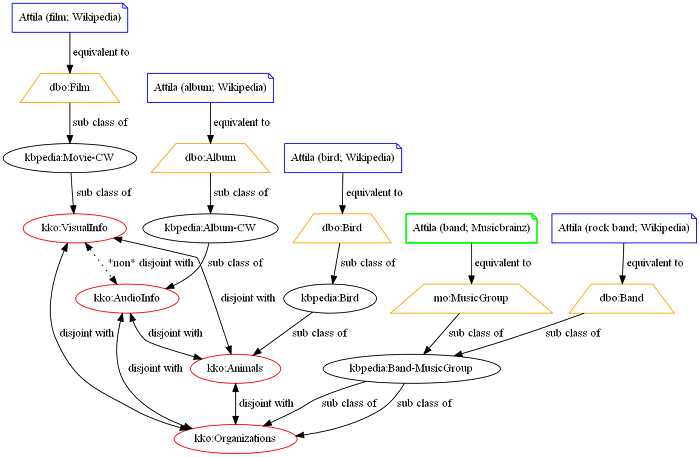
In this case the matching is unambiguous and the selection of the correct mapping to accept is obvious. However, most cases are not so simple to make a clear selection.
To illustrate a more common case, now let's say that the next entity to match from the Musicbrainz dataset is another entity called Attila, but this time it refers to Attila, the album by Mina. Since the basis of the comparison is different (comparing the Musicbrainz Attila album instead of the band), the entire process will yield different results. The main difference is that the album will be compared to a film and an album from the Wikipedia dataset. As you can notice in the graph below, these two entities belong to the super types kko:AudioInfo and kko:VisualInfo which are not disjoint.
(println "mo:MusicalWork -> dbo:Band" (.compare stc-ex-compare "http://purl.org/ontology/mo/MusicalWork" "http://dbpedia.org/ontology/Band")) (println "mo:MusicalWork -> dbo:Bird" (.compare stc-ex-compare "http://purl.org/ontology/mo/MusicalWork" "http://dbpedia.org/ontology/Bird")) (println "mo:MusicalWork -> dbo:Film" (.compare stc-ex-compare "http://purl.org/ontology/mo/MusicalWork" "http://dbpedia.org/ontology/Film")) (println "mo:MusicalWork -> dbo:Album" (.compare stc-ex-compare "http://purl.org/ontology/mo/MusicalWork" "http://dbpedia.org/ontology/Album"))
| Classes | Similarity |
|---|---|
| mo:MusicalWork -> dbo:Band | 0.2 |
| mo:MusicalWork -> dbo:Bird | 0.2 |
| mo:MusicalWork -> dbo:Film | 0.8762886597938144 |
| mo:MusicalWork -> dbo:Album | 0.9555555555555556 |
As you can see, the main difference is that we don't have a perfect match between the entities. We thus need to compare between their types, and two of the entities are ambiguous based on their SuperType (their super types are non-disjoint). In this case, what the SuperType Comparator does is to check the set of super classes of both entities, and calculate a similarity measure between the two sets of classes and compute a similarity measure. It is why we have 0.8762 for the possible Film match and 0.9555 for the possible Album match.
A musical work and an album are two nearly identical concepts. In fact, a musical work is a conceptual work of an album (a record). A musical work is also strongly related to films since films includes musical works, etc. However, the relationship between a musical work and an album is stronger than with a film and this is what the similarity measure shows.
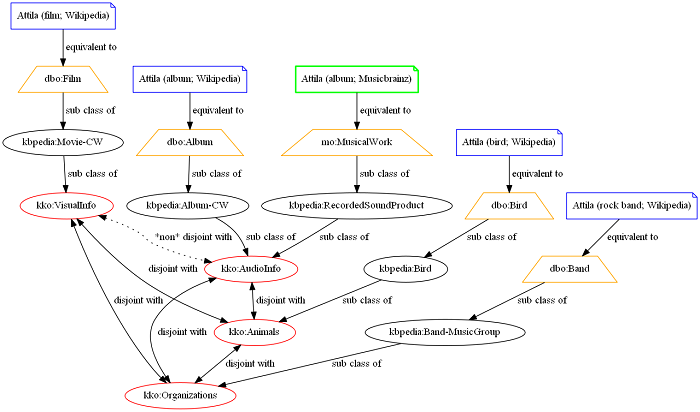
In this case, even if we have two ambiguous entities of an album and a film for which we don't have disjoint super types, we are still able to determine which one to choose to create the mapping based on the calculation of the similarity measure.
Conclusion
KBpedia has a rich structure and feature set upon which to base comparators for mapping purposes. While strings and labels are common to most mappers, the examples herein show the advantages of leveraging the typologies within KBpedia to remove many of the ambiguities between two sources. Further, even where there remains some ambiguity or lack of total disjointedness, the other information available for characterizing a given type proves useful to steer candidates to the more likely correct choice.
The usefulness of KBpedia to its potential purposes in entity recognition, relation extraction, categorization, sentiment analysis and the like requires that its base and mapped knowledge bases be highly accurate. The best way to prevent garbage out, is to limit garbage in. This quality ultimately depends on manual vettings to make sure final maps are indeed accurate, because language, usage and terminology will always diverge between information sources. The best way to deal with these issues at scale is to automate the generation of a limited number of candidates as much as possible, with the pool of candidates containing the "correct" mapping and best toward the top of the scored candidate list. Such automatic pre-processing of candidates speeds the eventual selection of the correct mappings.
These same capabilities are applicable not only for mapping datasets or knowledge bases together, but they are also quite effective to help with some machine learning tasks such as creating gold standards or curating detected unknown entities. It is quite effective to map external ontologies, schemas or vocabularies to KBpedia. The mapper is an essential tool for extending KBpedia to domain- and enterprise-specific needs.
|
|
|
KBpedia |
KBpedia exploits large-scale knowledge bases and semantic technologies for machine learning, data interoperability and mapping, and fact extraction and tagging.
Latest News
- KBpedia Adds Major eCommerce Capabilities 06/15/2020
- KBpedia Continues Quality Improvements 12/04/2019
- Wikidata Coverage Nearly Complete (98%) 04/08/2019
Other Resources
Contact Us
380 Knowling Drive
Coralville, IA 52241
U.S.A.
Voice: +1 319 621 5225
2016-2022 © Michael K. Bergman. All Rights Reserved.