USE CASE |
|
| Title: | Dynamic Machine Learning Using the KBpedia Knowledge Graph |
| Short Description: | The automated ways to select training sets and corpuses inherent with KBpedia, particularly in conjunction with setting up gold standards for analyzing test runs, enables much more time to be spent on refining the input data and machine learning parameters to obtain "best" results. |
| Problem: | After initial set-up or due to a change in the input data, we want to test and refine the parameters of our machine learners to obtain the best results. |
| Approach: | Because of the nearly automatic way to use KBpedia's knowledge structure to generate training sets and corpuses for machine learners, more time can be spent in the critical phases of testing and refining the actual choice and use of the learners. This efficiency also allows multiple learners to be combined for ensemble learning, and means that we can also devote time to improving the input data to generate the training sets for the learners.This use case highlights these capabilities by rapid testing of feature selection, hyperparameter optimization, and ensemble learning.. |
| Key Findings |
|
Another use case, Text Classification Using ESA and SVM, explains how one can use KBpedia to create positive and negative training sets automatically for different machine learning tasks. That use case explains how SVM classifiers may be trained and used to check if an input text belongs to the defined domain or not.
This current use case extends on this idea to explain how KBpedia can be used, along with other machine learning techniques, to cope with dynamic situations that may alter data or input assumptions. The variations we investigate are feature selection, hyperparameter optimization, and ensemble learning. The emphasis here is on the testing and refining of machine learners, versus the set up and configuration perspectives covered in other use cases.
Depending on the domain of interest, and depending on the required precision or recall, different strategies and techniques
can lead to better predictions. More often than not, multiple different training corpuses, learners and hyperparameters
need to be tested before ending up with the initial best possible prediction model. The key take away from this use case is that KBpedia can be used to automate fully the creation of a wide range of different training corpuses, to create models, to optimize their hyperparameters, and to evaluate those models.
New Knowledge Graph and Reasoning
One of the variations in this investigation is to look at the potential impact of a new version of KBpedia (version 1.10 in this case). A knowledge graph such as KBpedia is not static. It constantly evolves, gets fixed, and improves. New concepts are created, deprecated concepts are removed, new linkage to external data sources are created, etc. This growth means that any of these changes can have a [positive] impact on the creation of the positive and negative training sets. Applications based on KBpedia should be tested against any new knowledge graph that is released to see if its models will improve. Better concepts, better structure, and more linkages will often lead to better training sets as well.
Such growth in KBpedia (or in combination with domain information linked to it) is also why automating, and more importantly testing, this process is crucial. Upon the release of major new versions we are able to automate all of these steps to see the final impacts of upgrading the knowledge graph:
- Aggregate all the reference concepts that scope the specified domain (by inference)
- Create the positive and negative training corpuses
- Prune the training corpuses
- Configure the classifier (in this case, create the semantic vectors for ESA)
- Train the model (in this case, the SVM model)
- Optimize the hyperparameters of the algorithm (in this case, the linear SVM hyperparameters), and
- Evaluate the model on multiple gold standards.
Because each of these steps belongs to an automated workflow, we can easily check the impact of updating the KBpedia Knowledge Graph on our models.
Reasoning Over The Knowledge Graph
A new step we have added to this current use case is to use a reasoner to reason over the KBpedia knowledge graph. The reasoner is used when we define the scope of the domain to classify. We will browse the knowledge graph to see which seed reference concepts we should add to the scope. Then we will use a reasoner to extend the models to include any new sub-classes relevant to the scope of the domain. This means that we may add further specific features to the final model.
Update Domain Training Corpus Using KBpedia 1.10 and a Reasoner
Recall a prior use case used Music as its domain scope. The first step is to use updated KBpedia version 1.10 along with a reasoner to create the full scope of this updated Music domain.
The result of using this new version and a reasoner is that we now end up with 196 features (reference documents) instead of 64 with the previous version. This also means that we will have 196 documents in our positive training set if we only use the Wikipedia pages linked to these reference concepts (and not their related named entities).
(use 'cognonto-esa.core) (require '[cognonto-owl.core :as owl]) (require '[cognonto-owl.reasoner :as reasoner]) (def kbpedia-manager (owl/make-ontology-manager)) (def kbpedia (owl/load-ontology "resources/kbpedia_reference_concepts_linkage.n3" :manager kbpedia-manager)) (def kbpedia-reasoner (reasoner/make-reasoner kbpedia)) (define-domain-corpus ["http://kbpedia.org/kko/rc/Music" "http://kbpedia.org/kko/rc/Musician" "http://kbpedia.org/kko/rc/MusicPerformanceOrganization" "http://kbpedia.org/kko/rc/MusicalInstrument" "http://kbpedia.org/kko/rc/Album-CW" "http://kbpedia.org/kko/rc/Album-IBO" "http://kbpedia.org/kko/rc/MusicalComposition" "http://kbpedia.org/kko/rc/MusicalText" "http://kbpedia.org/kko/rc/PropositionalConceptualWork-MusicalGenre" "http://kbpedia.org/kko/rc/MusicalPerformer"] kbpedia "resources/domain-corpus-dictionary.csv" :reasoner kbpedia-reasoner)
Create Training Corpuses
The next step is to create the actual training corpuses: the general and domain ones. We have to load the dictionaries we created in the previous step, and then to locally cache and normalize the corpuses. Remember that the normalization steps are:
- Defluff the raw HTML page. We convert the HTML into text, and we only keep the body of the page
- Normalize the text with the following rules:
- remove diacritics characters
- remove everything between brackets like: [edit] [show]
- remove punctuation
- remove all numbers
- remove all invisible control characters
- remove all [math] symbols
- remove all words with 2 characters or fewer
- remove line and paragraph seperators
- remove anything that is not an alpha character
- normalize spaces
- put everything in lower case, and
- remove stop words.
(load-dictionaries "resources/general-corpus-dictionary.csv" "resources/domain-corpus-dictionary.csv") (cache-corpus) (normalize-cached-corpus "resources/corpus/" "resources/corpus-normalized/")
Create New Gold Standard
Because we never have enough instances in our gold standards to test against, let's create a third one, but this time adding a music related news feed that will add more positive examples to the gold standard.
(defn create-gold-standard-from-feeds [name] (let [feeds ["http://www.music-news.com/rss/UK/news" "http://rss.cbc.ca/lineup/topstories.xml" "http://rss.cbc.ca/lineup/world.xml" "http://rss.cbc.ca/lineup/canada.xml" "http://rss.cbc.ca/lineup/politics.xml" "http://rss.cbc.ca/lineup/business.xml" "http://rss.cbc.ca/lineup/health.xml" "http://rss.cbc.ca/lineup/arts.xml" "http://rss.cbc.ca/lineup/technology.xml" "http://rss.cbc.ca/lineup/offbeat.xml" "http://www.cbc.ca/cmlink/rss-cbcaboriginal" "http://rss.cbc.ca/lineup/sports.xml" "http://rss.cbc.ca/lineup/canada-britishcolumbia.xml" "http://rss.cbc.ca/lineup/canada-calgary.xml" "http://rss.cbc.ca/lineup/canada-montreal.xml" "http://rss.cbc.ca/lineup/canada-pei.xml" "http://rss.cbc.ca/lineup/canada-ottawa.xml" "http://rss.cbc.ca/lineup/canada-toronto.xml" "http://rss.cbc.ca/lineup/canada-north.xml" "http://rss.cbc.ca/lineup/canada-manitoba.xml" "http://feeds.reuters.com/news/artsculture" "http://feeds.reuters.com/reuters/businessNews" "http://feeds.reuters.com/reuters/entertainment" "http://feeds.reuters.com/reuters/companyNews" "http://feeds.reuters.com/reuters/lifestyle" "http://feeds.reuters.com/reuters/healthNews" "http://feeds.reuters.com/reuters/MostRead" "http://feeds.reuters.com/reuters/peopleNews" "http://feeds.reuters.com/reuters/scienceNews" "http://feeds.reuters.com/reuters/technologyNews" "http://feeds.reuters.com/Reuters/domesticNews" "http://feeds.reuters.com/Reuters/worldNews" "http://feeds.reuters.com/reuters/USmediaDiversifiedNews"]] (with-open [out-file (io/writer (str "resources/" name ".csv"))] (csv/write-csv out-file [["class" "title" "url"]]) (doseq [feed-url feeds] (doseq [item (:entries (feed/parse-feed feed-url))] (csv/write-csv out-file "" (:title item) (:link item) :append true))))))
This routine creates this third gold standard. Remember, we use the gold standard to evaluate different methods and models to classify an input text to see if it belongs to the domain or not.
For each piece of news aggregated in this manner, we manually determined if the candidate document belongs to the domain or not. This task is always the most time consuming part of the case. This task can be tricky, and requires a clear understanding of the proper scope for the domain. In this example, we consider an article to belong to the music domain if it mentions music concepts such as musical albums, songs, multiple music related topics, etc. If only a singer is mentioned in an article because he broke up with his girlfriend, without further mention of anything related to music, we don't classify it as being part of the domain.
[However, under a different interpretation of what should be in the domain wherein any mention of a singer qualifies, then we could extend the classification process to include named entities (the singer) extraction to help properly classify those articles. This revised scope is not used in this article, but it does indicate how your exact domain needs should inform such scoping and classification (tagging) decisions.]
You can download this new third gold standard from here.
Evaluate Initial Domain Model
Now that we have updated the training corpuses using the updated scope of the domain compared to the previous use case, let's analyze the impact of using a new version of KBpedia and to use a reasoner to increase the number of features in our model. Let's run our automatic process to evaluate the new models. The remaining steps that needs to be run are:
- Configure the classifier (in this case, create the semantic vectors for ESA)
- Train the model (in this case, the SVM model), and
- Evaluate the model on multiple gold standards.
Note: the see the full explanation of how ESA and the SVM classifiers works, please refer to the Text Classification Using ESA and SVM use case for more background information.
;; Load positive and negative training corpuses (load-dictionaries "resources/general-corpus-dictionary.csv" "resources/domain-corpus-dictionary.csv") ;; Build the ESA semantic interpreter (build-semantic-interpreter "base" "resources/semantic-interpreters/base/" (distinct (concat (get-domain-pages) (get-general-pages)))) ;; Build the vectors to feed to a SVM classifier using ESA (build-svm-model-vectors "resources/svm/base/" :corpus-folder-normalized "resources/corpus-normalized/") ;; Train the SVM using the best parameters discovered in the previous tests (train-svm-model "svm.w50" "resources/svm/base/" :weights {1 50.0} :v nil :c 1 :algorithm :l2l2)
Let's evaluate this model using our three gold standards:
(evaluate-model "svm.goldstandard.1.w50" "resources/gold-standard-1.csv")
True positive: 21
False positive: 3
True negative: 306
False negative: 6
Precision: 0.875
Recall: 0.7777778
Accuracy: 0.97321427
F1: 0.8235294
The performance changes related to the previous results (using KBpedia 1.02) are:
- Precision:
+10.33% - Recall:
-12.16% - Accuracy:
+0.31% - F1:
+0.26%
The results for the second gold standard are:
(evaluate-model "svm.goldstandard.2.w50" "resources/gold-standard-2.csv")
True positive: 16
False positive: 3
True negative: 317
False negative: 9
Precision: 0.84210527
Recall: 0.64
Accuracy: 0.9652174
F1: 0.72727275
The performances changes related to the previous results (using KBpedia 1.02) are:
- Precision:
+6.18% - Recall:
-29.35% - Accuracy:
-1.19% - F1:
-14.63%
What we can say is that the new scope for the domain greatly improved the precision of the model. This happens because
the new model is probably more complex and better scoped, which leads it to be more selective. However, because of this the
recall of the model suffers since some of the positive cases of our gold standard are not considered to be positive but
negative, which now creates new false positives. As you can see, there is almost always a tradeoff between precision
and recall. However, you could have 100% precision by only having one result right, but then the recall would suffer
greatly. This is why the F1 score is important since it is a weighted average of the precision and the recall.
Now let's look at the results of our new gold standard:
(evaluate-model "svm.goldstandard.3.w50" "resources/gold-standard-3.csv")
True positive: 28
False positive: 3
True negative: 355
False negative: 22
Precision: 0.9032258
Recall: 0.56
Accuracy: 0.9387255
F1: 0.69135803
Again, with this new gold standard, we can see the same pattern: the precision is pretty good, but the recall is not
that great since about half the true positives did not get noticed by the model.
Now, what could we do to try to improve this situation? The next thing we will investigate is to use feature selection and pruning.
Features Selection Using Pruning and Training Corpus Pruning
A new method that we will investigate to try to improve the performance of the models is called feature selection. As its name says, what we are doing is to select specific features to create our prediction model. The idea here is that not all features are born equal and different features may have different (positive or negative) impacts on the model.
In our specific use case, we want to do feature selection using a pruning technique. What we will do is to count the number of tokens for each of our features, and each of the Wikipedia pages related to these features. If the number of tokens in an article is too small (below 100), then we will drop that feature.
[Note: feature selection is a complex topic; other options and nuances are not further discussed here.]
The idea here is not to give undue importance to a feature for which we lack proper positive documents in the training corpus. Depending on the feature, it may, or may not, have an impact on the overall model's performance.
Pruning the general and domain specific dictionaries is really simple. We only have to read the current dictionaries, to read each of the documents mentioned in the dictionary from the cache, to calculate the number of tokens in each, and then to keep them or to drop them if they reach a certain threshold. Finally we write a new dictionary with the pruned features and documents:
(defn create-pruned-pages-dictionary-csv [dictionary-file prunned-file normalized-corpus-folder & {:keys [min-tokens] :or {min-tokens 100}}] (let [dictionary (rest (with-open [in-file (io/reader dictionary-file)] (doall (csv/read-csv in-file))))] (with-open [out-file (io/writer prunned-file)] (csv/write-csv out-file (->> dictionary (mapv (fn [[title rc]] (when (.exists (io/as-file (str normalized-corpus-folder title ".txt"))) (when (> (->> (slurp (str normalized-corpus-folder title ".txt")) tokenize count) min-tokens) [[title rc]])))) (apply concat) (into []))))))
Then we can prune the general and domain specific dictionaries using this simple function:
(create-pruned-pages-dictionary-csv "resources/general-corpus-dictionary.csv" "resources/general-corpus-dictionary.pruned.csv" "resources/corpus-normalized/" min-tokens 100) (create-pruned-pages-dictionary-csv "resources/domain-corpus-dictionary.csv" "resources/domain-corpus-dictionary.pruned.csv" "resources/corpus-normalized/" min-tokens 100)
As a result of this specific pruning approach, the number of features drops from 197 to 175.
Evaluating Pruned Training Corpuses and Selected Features
Now that the training corpuses have been pruned, let's load them and then evaluate their performance on the gold standards.
;; Load positive and negative pruned training corpuses (load-dictionaries "resources/general-corpus-dictionary.pruned.csv" "resources/domain-corpus-dictionary.pruned.csv") ;; Build the ESA semantic interpreter (build-semantic-interpreter "base" "resources/semantic-interpreters/base-pruned/" (distinct (concat (get-domain-pages) (get-general-pages)))) ;; Build the vectors to feed to a SVM classifier using ESA (build-svm-model-vectors "resources/svm/base-pruned/" :corpus-folder-normalized "resources/corpus-normalized/") ;; Train the SVM using the best parameters discovered in the previous tests (train-svm-model "svm.w50" "resources/svm/base-pruned/" :weights {1 50.0} :v nil :c 1 :algorithm :l2l2)
Let's evaluate this model using our three gold standards:
(evaluate-model "svm.pruned.goldstandard.1.w50" "resources/gold-standard-1.csv")
True positive: 21
False positive: 2
True negative: 307
False negative: 6
Precision: 0.9130435
Recall: 0.7777778
Accuracy: 0.97619045
F1: 0.84000003
The performances changes related to the initial results (using KBpedia 1.02) are:
- Precision:
+18.75% - Recall:
-12.08% - Accuracy:
+0.61% - F1:
+2.26%
In this case, compared with the previous results (non-pruned with KBpedia 1.10), we improved the precision without
decreasing the recall which is the ultimate goal. This means that the F1 score increased by 2.26% just by pruning, for this gold standard.
The results for the second gold standard are:
(evaluate-model "svm.goldstandard.2.w50" "resources/gold-standard-2.csv")
True positive: 16
False positive: 3
True negative: 317
False negative: 9
Precision: 0.84210527
Recall: 0.64
Accuracy: 0.9652174
F1: 0.72727275
The performances changes related to the previous results (using KBpedia 1.02) are:
- Precision:
+6.18% - Recall:
-29.35% - Accuracy:
-1.19% - F1:
-14.63%
In this case, the results are identical (with non-pruned with KBpedia 1.10). Pruning did not change
anything. Considering the relatively small size of the gold standard, this is to be expected since the model also did not
drastically change.
Now let's look at the results of our new gold standard:
(evaluate-model "svm.goldstandard.3.w50" "resources/gold-standard-3.csv")
True positive: 27
False positive: 7
True negative: 351
False negative: 23
Precision: 0.7941176
Recall: 0.54
Accuracy: 0.9264706
F1: 0.64285713
Now let's check how these compare to the non-pruned version of the training corpus:
- Precision:
-12.08% - Recall:
-3.7% - Accuracy:
-1.31% - F1:
-7.02%
Both false positives and false negatives increased with this change, which also led to a decrease in the overall metrics. What happened?
Different things may have happened in fact. Maybe the new set of features is not optimal, or maybe the hyperparameters of the SVM classifier are offset. This is what we will try to figure out by working with two new methods that we will use to try to continue to improve our model: hyperparameters optimization using grid search and using ensembles learning.
Hyperparameters Optimization Using Grid Search
Hyperparameters are parameters that are not learned by the estimators. They are a kind of configuration option for an
algorithm. In the case of a linear SVM, hyperparameters are C, epsilon, weight and the algorithm used. Hyperparameter
optimization is the task of trying to find the right parameter values in order to optimize the performance of the model.
There are multiple different strategies that we can use to try to find the best values for these hyperparameters, but the one we will highlight here is called the grid search, which exhaustively searches across a manually listing of possible hyperparameter values.
The grid search function we want to define will enable us to specify the algorithm(s), the weight(s), C and the
stopping tolerence. Then we will want the grid search to keep the hyperparameters that optimize the
score of the metric we want to focus on. We also have to specify the gold standard we want to use to evaluate the
performance of the different models.
Here is the function that implements that grid search algorithm:
(defn svm-grid-search [name model-path gold-standard & {:keys [grid-parameters selection-metric] :or {grid-parameters [{:c [1 2 4 16 256] :e [0.001 0.01 0.1] :algorithm [:l2l2] :weight [1 15 30]}] selection-metric :f1}}] (let [best (atom {:gold-standard gold-standard :selection-metric selection-metric :score 0.0 :c nil :e nil :algorithm nil :weight nil}) model-vectors (read-string (slurp (str model-path "model.vectors")))] (doseq [parameters grid-parameters] (doseq [algo (:algorithm parameters)] (doseq [weight (:weight parameters)] (doseq [e (:e parameters)] (doseq [c (:c parameters)] (train-svm-model name model-path :weights {1 (double weight)} :v nil :c c :e e :algorithm algo :model-vectors model-vectors) (let [results (evaluate-model name gold-standard :output false)] (println "Algorithm:" algo) (println "C:" c) (println "Epsilon:" e) (println "Weight:" weight) (println selection-metric ":" (get results selection-metric)) (println) (when (> (get results selection-metric) (:score @best)) (reset! best {:gold-standard gold-standard :selection-metric selection-metric :score (get results selection-metric) :c c :e e :algorithm algo :weight weight})))))))) @best))
The possible algorithms are:
:l2lr_primal:l2l2:l2l2_primal:l2l1:multi:l1l2_primal:l1lr:l2lr
To simplify things a little bit for this task, we will merge the three gold standards we have into one. We will use that gold standard moving forward. The merged gold standard can be downloaded from here. We now have a single gold standard with 1017 manually vetted web pages.
Now that we have a new consolidated gold standard, let's calculate the performance of the models when the training corpuses are pruned or not. This will become the new basis to compare the subsequent results ifor this use case. The metrics when the training corpuses are pruned:
True positive: 56 false positive: 10 True negative: 913 False negative: 38
Precision: 0.8484849 Recall: 0.59574467 Accuracy: 0.95280236 F1: 0.7
Now, let's run the grid search that will try to optimize the F1 score of the model using the pruned training corpuses and using the full gold standard:
(svm-grid-search "grid-search-base-pruned-tests" "resources/svm/base-pruned/" "resources/gold-standard-full.csv" :selection-metric :f1 :grid-parameters [{:c [1 2 4 16 256] :e [0.001 0.01 0.1] :algorithm [:l2l2] :weight [1 15 30]}])
{:gold-standard "resources/gold-standard-full.csv"
:selection-metric :f1
:score 0.7096774
:c 2
:e 0.001
:algorithm :l2l2
:weight 30}
With a simple subset of the possible hyperparameter space, we found that by increasing the c parameter to 2 we could improve
the performance of the F1 score on the gold standard by 1.37%. It is not a huge gain, but it is still an appreciable
gain given the miinimal effort invested so far (basically: waiting for the grid search to finish). Subsequently we could tweak the
subset of parameters to try to improve a little further. Let's try with c = [1.5, 2, 2.5] and weight = [30, 40]. Let's
also try to check with other algorithms as well like L2-regularized L1-loss support vector regression (dual).
The goal here is to configure the initial grid search with general parameters with a wide range of possible values. Then subsequently we can use that tool to fine tune some of the parameters that were returning good results. In any case, the more computer power and time you have, the more tests you will be able to perform.
Ensemble Learning With SVM
Now that we have good hyperparameters for a single linear SVM classifier, let's try another technique to improve the performance of the system: ensemble learning.
So far, we already reached 95% of accuracy with some tweaking the hyperparameters and the training corpuses but the F1
score is still around ~70% with the full gold standard which can be improved. There are also situations when precision should be nearly perfect (because false positives are really not acceptable) or when the recall should be optimized.
Here we will try to improve this situation by using ensemble learning. It uses multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone. In our examples, each model will have a vote and the weight of the vote will be equal for each mode. We will use five different strategies to create the models that will belong to the ensemble:
- Bootstrap aggregating (bagging)
- Asymmetric bagging 1
- Random subspace method (feature bagging)
- Asymmetric bagging + random subspace method (ABRS) 1
- Bootstrap aggregating + random subspace method (BRS)
Different strategies will be used depending on different things like: are the positive and negative training documents unbalanced? How many features does the model have? etc. Let's introduce each of these different strategies.
Note that in this use case we are only creating ensembles with linear SVM learners. However an ensemble can be composed of multiple different kind of learners, like SVM with non-linear kernels, decisions trees, etc. However, to simplify this use case, we will stick to a single linear SVM with multiple different training corpuses and features.
Strategies
Bootstrap Aggregating (bagging)
The idea behind bagging is to draw a subset of positive and negative training samples at random and with replacement. Each model of the ensemble will have a different training set but some of the training sample may appear in multiple different training sets.
Asymmetric Bagging
Asymmetric Bagging has been proposed by Tao, Tang, Li and Wu 1. The idea is to use asymmetric bagging when the number of positive training samples is largely unbalanced relatively to the negative training samples. The idea is to create a subset of random (with replacement) negative training samples, but by always keeping the full set of positive training samples.
Random Subspace method (feature bagging)
The idea behind feature bagging is the same as bagging, but works on the features of the model instead of the training sets. It attempts to reduce the correlation between estimators (features) in an ensemble by training them on random samples of features instead of the entire feature set.
Asymmetric Bagging + Random Subspace method (ABRS)
Asymmetric bagging and the random subspace method have also been proposed by Tao, Tang, Li and Wu 1. The problems they had with their content-based image retrieval system are the same we have with this kind of automatic training corpuses generated from knowledge graph:
- SVM is unstable on small-sized training set
- SVM's optimal hyperplane may be biased when the positive training sample is much less than the negative feedback sample (this is why we used weights in this case), and
- The training set is smaller than the number of features in the SVM model.
The third point is not immediately an issue for us (except if you have a domain with many more features than we had in our example), but becomes one when we start using asymmetric bagging.
What we want to do here is to implement asymmetric bagging and the random subspace method to create 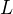 number of individual models. This method is called ABRS-SVM which stands for Asymmetric Bagging Random Subspace Support Vector Machines.
number of individual models. This method is called ABRS-SVM which stands for Asymmetric Bagging Random Subspace Support Vector Machines.
The algorithm we will use is:
- Let the number of positive training documents be
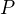 , the number of negative training document be
, the number of negative training document be 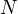 and the number of features in the training data be
and the number of features in the training data be 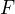 .
. - Choose to be the number of individual models in the ensemble.
- For all individual model
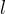 , choose
, choose 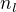 where
where 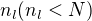 to be the number of negative training documents for
to be the number of negative training documents for 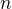
- For all individual models , choose
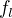 where
where 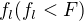 to be the number of input variables for
to be the number of input variables for 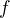 .
. - For each individual model , create a training set by choosing features from with replacement, by choosing negative training documents from with replacement, by choosing all positive training documents and then train the model.
Bootstrap Aggregating + Random Subspace method (BRS)
Bagging with features bagging is the same as asymmetric bagging with the random subspace method except that we use bagging instead of asymmetric bagging. (ABRS should be used if your positive training sample is severely unbalanced compared to your negative training sample. Otherwise BRS should be used.)
SVM Learner
We use the linear Semantic Vector Machine (SVM) as the learner to use for the ensemble. What we will be creating is a series of SVM models that will be different depending on the ensemble method(s) we will use to create the ensemble.
Build Training Document Vectors
The first step we have to do is to create a structure where all the positive and negative training documents will have
their vector representation. Since this is the task that takes the most computer time in the whole process, we will calculate
them using the (build-svm-model-vectors) function and we will serialize the structure on the file system. That way, to create the ensemble's models, we will only have to load it from the file system without having the re-calculate it each time.
Train, Classify and Evaluate Ensembles
The goal is to create a set of X number of SVM classifiers where each of them use different models. The models can
differ in their features or their training corpus. Then each of the classifier will try to classify an input text
according to their own model. Finally each classifier will vote to determine if that input text belong, or not, to the
domain.
There are four hyperparameters related to ensemble learning:
- The mode to use
- The number of models we want to create in the ensemble
- The number of training documents we want in the training corpus, and
- The number of features.
Other hyperparameters could include the ones of the linear SVM classifier, but in this example we will simply reuse the best parameters we found above. We now train the ensemble using the (train-ensemble-svm) function.
Once the ensemble is created and trained, then we have to use the (classify-ensemble-text) function to classify an input text
using the ensemble we created. That function takes two parameters: :mode, which is the ensemble's mode, and
:vote-acceptance-ratio, which defines the number of positive votes that is required such that the ensemble positively
classify the input text. By default, the ratio is 50%, but if you want to optimize the precision of the ensemble, then
you may want to increase that ratio to 70% or even 95% as we will see below.
Finally the ensemble, configured with all its hyperparameters, will be evaluated using the (evaluate-ensemble) function,
which is the same as the (evaluate-model) function, but which uses the ensemble instead of a single SVM model to classify
all of the articles. As before, we will characterize the assignments in relation to the gold standard.
Let's now train different ensembles to try to improve the performance of the system.
Asymmetric Bagging
The current corpus training set is highly unbalanced. This is why the first test we will do is to apply the asymmetric bagging strategy. What this does is that each of the SVM classifiers will use the same positive training set with the same number of positive documents. However, each of them will take a random number of negative training documents (with replacement).
(use 'cognonto-esa.core) (use 'cognonto-esa.ensemble-svm) (load-dictionaries "resources/general-corpus-dictionary.pruned.csv" "resources/domain-corpus-dictionary.pruned.csv") (load-semantic-interpreter "base-pruned" "resources/semantic-interpreters/base-pruned/") (reset! ensemble []) (train-ensemble-svm "ensemble.base.pruned.ab.c2.w30" "resources/ensemble-svm/base-pruned/" :mode :ab :weight {1 30.0} :c 2 :e 0.001 :nb-models 100 :nb-training-documents 3500)
Now let's evaluate this ensemble with a vote acceptance ratio of 50%
(evaluate-ensemble "ensemble.base.pruned.ab.c2.w30" "resources/gold-standard-full.csv" :mode :ab :vote-acceptance-ratio 0.50)
True positive: 48
False positive: 6
True negative: 917
False negative: 46
Precision: 0.8888889
Recall: 0.5106383
Accuracy: 0.9488692
F1: 0.6486486
Let's increase the vote acceptance ratio to 90%:
(evaluate-ensemble "ensemble.base.pruned.ab.c2.w30" "resources/gold-standard-full.csv" :mode :ab :vote-acceptance-ratio 0.90)
True positive: 37
False positive: 2
True negative: 921
False negative: 57
Precision: 0.94871795
Recall: 0.39361703
Accuracy: 0.94198626
F1: 0.556391
In both cases, the precision increases considerably compared to the non-ensemble learning results. However, the recall
did drop at the same time, which dropped the F1 score as well. Let's now try with the ABRS method
Asymmetric Bagging + Random Subspace method (ABRS)
The goal of the random subspace method is to select a random set of features. This means that each model will have their own feature set and will make predictions according to them. With the ABRS strategy, we will conclude with highly different models since none will have the same negative training sets nor the same features.
Here what we test is to define each classifier with 65 randomly chosen features out of 174 to restrict the negative
training corpus to 3500 randomly selected documents. Then we choose to create 300 models to try to get a really
heterogeneous population of models.
(reset! ensemble []) (train-ensemble-svm "ensemble.base.pruned.abrs.c2.w30" "resources/ensemble-svm/base-pruned/" :mode :abrs :weight {1 30.0} :c 2 :e 0.001 :nb-models 300 :nb-features 65 :nb-training-documents 3500)
(evaluate-ensemble "ensemble.base.pruned.abrs.c2.w30" "resources/gold-standard-full.csv" :mode :abrs :vote-acceptance-ratio 0.50)
True positive: 41
False positive: 3
True negative: 920
False negative: 53
Precision: 0.9318182
Recall: 0.43617022
Accuracy: 0.9449361
F1: 0.59420294
For these features and training sets, using the ABRS method did not improve on the AB method we tried above.
Conclusion
This use case shows three totally different ways to use KBpedia (and any domain extensions that may be employed) to create positive and negative training sets automatically. We demonstrated how the full process can be automated where the only requirement is to get a list of seed KBpedia reference concepts.
We also quantified the impact of using new versions of KBpedia, and how different strategies, techniques or algorithms can have different impacts on the prediction models.
Creating prediction models using supervised machine learning algorithms (which is currently the bulk of the learners currently used) has two global steps:
- Label training sets and generate gold standards, and
- Test, compare, and optimize different learners, ensembles and hyperparameters.
Unfortunately, today, given the manual efforts required by the first step, the overwhelming portion of time and budget is spent here to create a prediction model. By automating much of this process, KBpedia substantially reduces this effort. Time and budget can now be re-directed to the second step of "dialing in" the learners, where the real payoff occurs.
Further, as we also demonstrated, once we automate this process of labeling and reference standards, then we can also automate the testing and optimization of multiple prediction algorithms, hyperparameters configuration, etc. In short, for both steps, KBpedia provides significant reductions in time and effort to get to desired results.
Footnotes:
|
|
|
KBpedia |
KBpedia exploits large-scale knowledge bases and semantic technologies for machine learning, data interoperability and mapping, and fact extraction and tagging.
Latest News
- KBpedia Adds Major eCommerce Capabilities 06/15/2020
- KBpedia Continues Quality Improvements 12/04/2019
- Wikidata Coverage Nearly Complete (98%) 04/08/2019
Other Resources
Contact Us
380 Knowling Drive
Coralville, IA 52241
U.S.A.
Voice: +1 319 621 5225
2016-2022 © Michael K. Bergman. All Rights Reserved.