FAQ
- Where does the name 'KBpedia' come from?
- Knowledge-based AI is a new field for me; how can I get up to speed quickly?
- Where can I learn more about Charles Sanders Peirce?
- How do Peirce's Universal Categories actually influence KBpedia's design?
- What is a 'knowledge graph'?
- What is 'distant supervision'?
- But how does this compare to what I keep hearing about 'deep learning'?
- So is KBAI somehow related to all of this?
- How come when I search for XXX in the knowledge graph I do not see an autocomplete entry? I'm sure it must be in the system.
- There seems to be a lot of structure or features in KBpedia; where is a good overview?
- How come two other large, public knowledge bases, Yago and Freebase, are not part of the "core" KBpedia?
- How big is KBpedia?
- I see occasional errors on the site. Why is that, and what is the overall quality level of KBpedia?
- What is the status of OpenCyc in KBpedia's constituent knowledge bases?
- There's alot going on with this site; how does it all work?
- Who supplied the icons on this site?
- What are the sources for the percent improvement from using KBpedia?
Where does the name 'KBpedia' come from?
The term 'KBpedia' is a portmanteau of "knowledge base (KB)" and "encyclopedia", which represents our semantic and knowledge graph approach to artificial intelligence. The name is meant to honor Wikipedia and DBpedia, two constituent KBs of the system.
Knowledge-based AI is a new field for me; how can I get up to speed quickly?
Knowledge-based artificial intelligence, or KBAI, is a branch of artificial intelligence focused on knowledge-based systems. A good introduction is the Knowledge-based Artificial Intelligence article. How knowledge bases can be a rich source of features (or input variables) to training machine learners is described in the A (Partial) Taxonomy of Machine Learning Features article. You can supplement these intros with further detail on KBAI and Charles Peirce, who set the logic basis for much of KBpedia.
Where can I learn more about Charles Sanders Peirce?
Actually, there is a quite excellent set of starting articles about Charles Sanders Peirce (pronounced "purse") on Wikipedia. Additional links under the Peirce category and external links from there should get you on your way.
How do Peirce's Universal Categories actually influence KBpedia's design?
The entire upper structure category system for the KBpedia Knowledge Ontology is based on our understanding of Peirce's Universal Categories of Firstness, Secondness and Thirdness. KKO can also be downloaded and inspected in an ontology editor such as Protege. The KKO upper structure provides the tie-in to KBpedia's 30 or so "core" typologies.
What is a 'knowledge graph'?
A 'knowledge graph' is an ontology; that is, an organized network of related and interconnected concepts. Specific things (or objects) in the given domain are represented as nodes in the graph, with edges or connections between those nodes representing the relationships between things. Knowledge graphs (ontologies), if organized in a coherent and consistent manner, may be reasoned over and used to select and inspect related things.
What is 'distant supervision'?
Machine learning is most often split into supervised and unsupervised learning. Supervised learning uses labeled inputs as the objective functions to train the learners; unsupervised learning requires no labeling in advance. For knowledge and natural language purposes, supervised typically works the best, but is more time consuming and costly. Distant supervision is a way to reduce these costs by leveraging the labels that already exist in knowledge bases or vetted knowledge sources. Semi-supervised is another variant that uses both labeled and unlabeled data.
But how does this compare to what I keep hearing about 'deep learning'?
Deep learning is based on a variety of so-called neural nets, and is an iterative technique where each learning iteration forms a layer of new results, which provide the feature inputs for the next iteration (layer). In knowledge and NLP applications, existing labels (supervision) are often used as part of the feature inputs. Unsupervised may also be used to generate new features or structure. Having "feature richness", including much labeled data, which KBAI provides, appears to work best for deep learning applied to knowledge representation or natural language.
So is KBAI somehow related to all of this?
Absolutely. Knowledge-based artificial intelligence has the ideal of massively labeled, logical reasonable, and coherently organized knowledge structures and language. The What is KBAI? page describes how these kinds of "feature rich" knowledge bases help promote both supervised and unsupervised learning, and are also good substrates for deep learning. Moreover, KBAI knowledge structures also lend themselves to quicker and more effective mapping to external schema and data.
How come when I search for XXX in the knowledge graph I do not see an autocomplete entry? I'm sure it must be in the system.
Yeah, this is a limitation of the current KBpedia search function. Right now, KBpedia search is focused on the use of reference concepts (RCs) as the entry points. Though millions of entities may be found by navigating the graph, these are not yet indexed in the KBpedia search function. We are working on this, and will announce when this enhanced search function is available.
There seems to be a lot of structure or features in KBpedia; where is a good overview?
Yes, by design, KBpedia is optimized to expose the most structure (features) possible in the underlying knowledge bases. A summary of these structures is provided in the KKO Structural Components page.
How come two other large, public knowledge bases, YAGO and Freebase, are not part of the "core" KBpedia?
In fact, there are some Freebase mappings on KBpedia. We did not formally include Freebase because it has been shut down by Google, with migration of some parts of it to Wikidata. As for YAGO, a system we like and have been involved with from its first release in 2008, we do not include it because its conceptual basis in WordNet is different than the conceptual underpinnings of KBpedia. WordNet is a lexical vocabulary, and not of concepts and entities.
How big is KBpedia?
There is no single, agreed-upon metric for measuring the size of knowledge bases. Nonetheless, we try to capture the size of KBpedia through a number of measures, as shown on the KBpedia statistics page. There are 58,000 reference concepts, 40 million entities, 3.5+ billion direct assertions, and nearly 7 billion inferred facts on KBpedia.
I see occasional errors on the site. Why is that, and what is the overall quality level of KBpedia?
The human eye has an uncanny ability to pick out things that are not level or that are out of plumb. Similarly, when we scan results or result lists, we can often quickly see the errors or misassignments. Machine systems in information retrieval and connecting data are deemed "very good" when their accuracy rates are over 95%, and are generally viewed as "excellent" when they are over 98%. But in a system of millions of assertions, such as KBpedia, a 98% accuracy rate still translates into 20,000 errors per 1 million assertions! That is quite a large amount. Because of its high degree of manual vetting, we estimate the accuracy of KBpedia to be over 99%, but that still masks many errors and misassignments. (We discover them ourselves on a routine basis, and for which we apply automated quality and consistency checks.) We are committed to get this error rate as low as possible, which is why we include a prominent red button on many screens to flag observed errors. Please, when you see a problem, let us know!
What is the status of OpenCyc in KBpedia's constituent knowledge bases?
Shortly after the initial release of KBpedia in early 2017, Cycorp announced it was ceasing support of the open source version of Cyc, OpenCyc. Since literally tens of thousands of downloads had occurred for OpenCyc since its initial release in 2002, and because many key structural relationships in KBpedia were informed by OpenCyc, we have retained these linkages. See further the page on OpenCyc for more information.
There's alot going on with this site; how does it all work?
The two major working portions of the site are the demo and the interactive knowledge graph. About the Demo is the help page for the demo. The KG is explained in the How to Use the Knowledge Graph page.
Who supplied the icons on this site?
The Interface and Web icons are designed by Freepik and distributed by Flaticon.
What are the sources for the percent improvement from using KBpedia?
The data preparation effort estimates come from Figure Eight.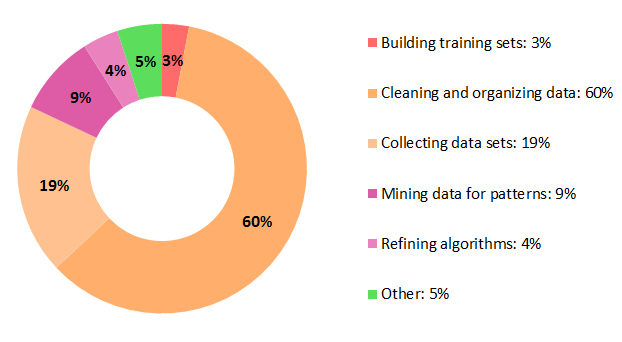

|
|
|
KBpedia |
KBpedia exploits large-scale knowledge bases and semantic technologies for machine learning, data interoperability and mapping, and fact extraction and tagging.
Latest News
- KBpedia Adds Major eCommerce Capabilities 06/15/2020
- KBpedia Continues Quality Improvements 12/04/2019
- Wikidata Coverage Nearly Complete (98%) 04/08/2019
Other Resources
Contact Us
380 Knowling Drive
Coralville, IA 52241
U.S.A.
Voice: +1 319 621 5225
2016-2022 © Michael K. Bergman. All Rights Reserved.